
The Unified Profile
03 Jul 2022 » Platform
One of the first clarifications I need to make about Adobe Experience Platform (AEP) when I start working with a new client is that it is not your typical database. People are used to relational databases and NoSQL databases, so, naturally, they try to classify AEP into a known category. I would dare to say that CDPs should have their own category.
Profiles
When working with traditional databases, you can use them to store any kind of data: customers, sales, marketing campaigns, payroll data, employees… However, when you work with a CDP, there is only one thing that you care about: people. It is so much so, that, except for some special cases, in AEP there is only one “table”: the profile. I am using here the word “table” as this is probably the most common way of understanding it. You should remember that this is just an analogy and that there is no such a table in the traditional sense.
In case you are wondering what a profile is, you could picture it as an entry in this hypothetical database. In other words, it is all the information you have in the CDP about an individual.
As you work more with AEP, you will see that everything you do revolves around profiles:
- Schemas. They define what the profile should look like. Schemas are defined following the XDM.
- Datasets. They contain the data of the profiles, following the structure of a schema.
- Segments. Segments use schema parameters to select profiles.
- Destinations. The output of a segment is a list of profiles, which are sent to a destination.
Fragments
As I explained in my post on XDM, a CDP ingests data from multiple data sources:
- CRM information
- Web or app behaviour
- Transactions
- Email interactions
- Etc.
Although marketers would love to know every single detail about their customers and prospects, the reality is that we only have partial data from these profiles:
- If a person has only visited the website anonymously, we will only have a cookie (usually an ECID) and its associated clickstream.
- We will not have any transactional data from a person who has never purchased anything.
- Someone who only goes to the brick-and-mortar shop will not have any web behaviour.
- We cannot have any email interactions from someone who has not shared their email address.
In other words, all we know about a profile are fragments of information. It is also worth noting that we will have a different number of fragments for each profile and that it is quite unlikely that we have a high number of profiles with all their fragments. If I compare it with a relational database, this means that, in the customers’ table, for every row, there are some or many columns with a NULL.
One final important detail about fragments is that it has to have one or more identities. I know it sounds obvious, but I just want to make it clear. Without one, how can we know to who the fragment belongs?
The best image to visualize the concept of fragments is from the video on this help page:
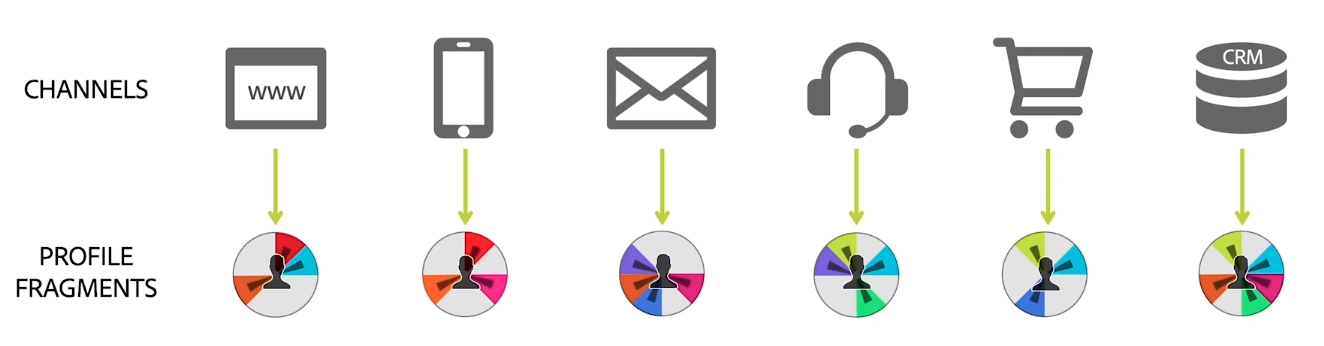
Enabling for profile
One concept that you have probably heard in AEP projects is “enabling for profile”. This may sound initially weird: why would you want to have this setting? If I am sending data to AEP, it is to build a profile, right?
The reality is that it is not always needed. There are some use cases where you do not need to have a profile. Some examples are:
- Lookup tables
- Customer Journey Analytics
- Using Query Service
How is this organized internally? Without getting into technicalities, AEP has two separate data stores: the data lake and the profile store. All data that goes into AEP is stored in the data lake. However, only some of it ends up in the profile store. One condition to get fragments into the profile store is to enable them for profile.
In summary, if you want a fragment to be considered in a profile, its associated schema and dataset must be enabled for profile.
The Unified Profile
Finally, we get to the unified profile. As we have just seen, from different data sources we get different fragments for the same profile. The last step is to combine all these fragments into a single profile. This is why we call it the Unified Profile. Following the image above, this is what it looks like:
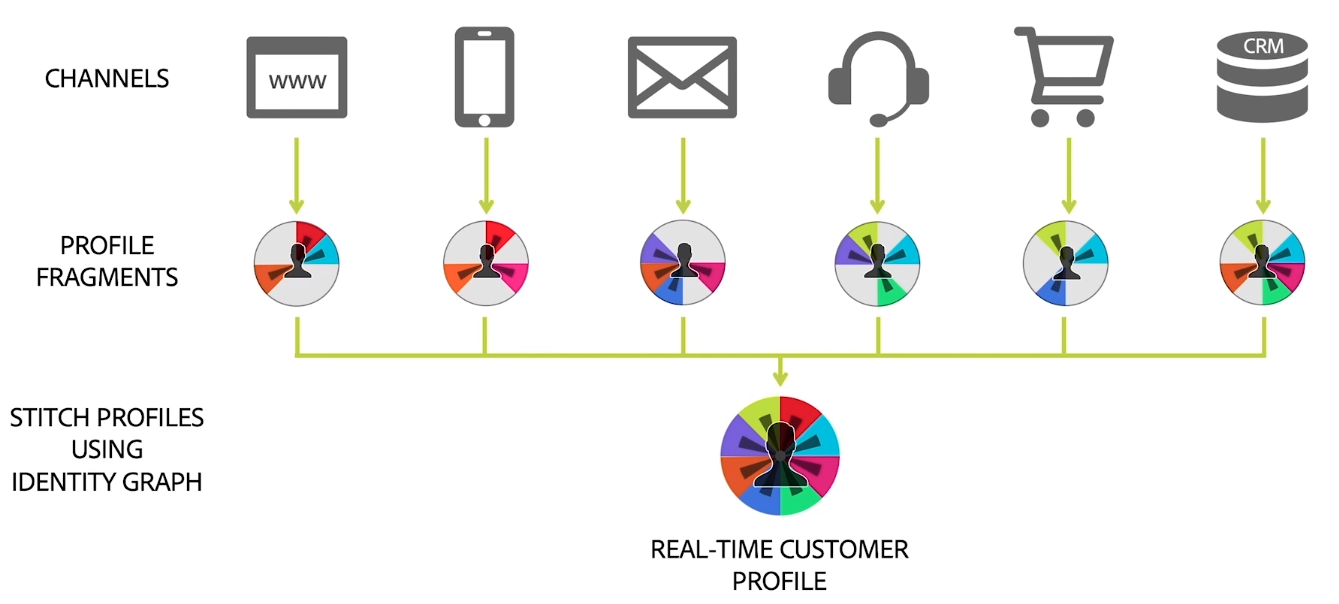
The way I like to imagine it working (I do not know exactly how it actually works) is as follows:
- You start with one identity
- Using the identity graph, AEP looks for all other identities that are associated with this one
- AEP retrieves all the known fragments for these identities
- It combines the fragments into a profile
This final result is the profile that we will be working on when it comes to segmentation and activation.
Merge policies
If you have reviewed in detail the previous image, you will have noticed that some fragments can come from various data sources. For example, the red fragment is provided by both the web and app data sources. The obvious question is: which one will AEP use?
This is where merge policies come into the picture. With them, you define which one to choose in each case. There are two options:
- Time-based: use the latest fragment based on its timestamp.
- Priorities: determine which datasets (i.e. data sources) are more reliable and put them at the top, leaving the less reliable ones at the bottom of your list.
So, whenever there is a collision of fragments, AEP will know which one to choose.
Caveats
All the explanation in this post has excluded lookup tables and tables from the RT-CDP B2B edition. I have only referred to the XDM Individual Profile.
Photo by Wylly Suhendra on Unsplash