
Server-side Implementation
09 Apr 2023 » Server Side
A few weeks ago, Chenna asked me how a developer should approach a server-side implementation of the Adobe Experience Cloud tools. I am afraid there is no universal answer to this question, as it depends entirely on the Content Management System and the Content Delivery Network. However, I will give some clues on how I would do it and some details to consider.
Content Management System
If you want a pure server-side implementation, your code needs to run as part of the page assembly in your Content Management System (CMS). This is how I showed it in the code I presented during the EMEA Summit 2019. The following steps present a generic solution:
- The browser requests an HTML page to the CMS.
- The CMS receives the request, parses it, retrieves the content from the database and generates an HTML page.
- A custom code is now invoked to do the following:
- If there is no ECID in the request (AMCV cookie), request the ECID server-side.
- Make a call to the Adobe Target delivery API. We usually refer to this call as an mbox call.
- Process the response from Adobe Target. If this response contains alternative content, modify the HTML page generated by the CMS in step 2 according to the response.
- Send the updated version of the HTML page back to the browser.
- Run another custom code to send the Adobe Analytics beacon.
If you prefer a diagram, this is how it would look like:
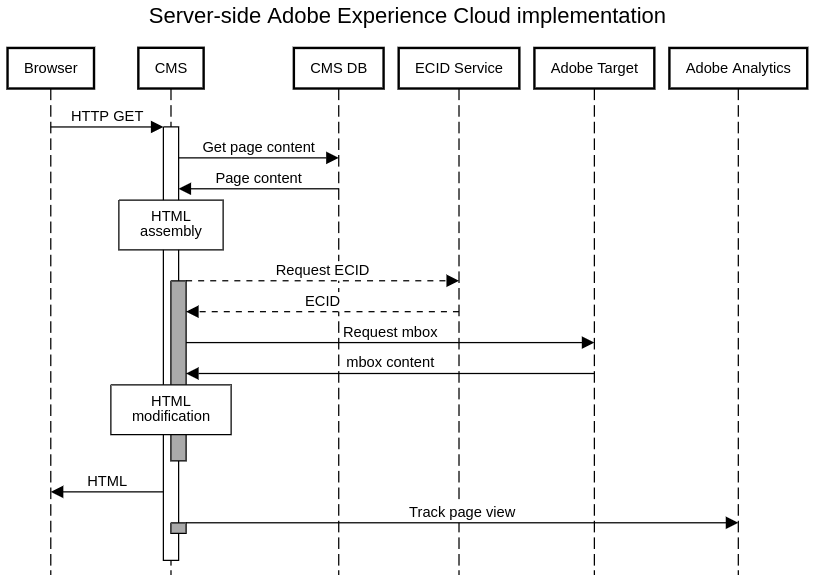
As a developer, you will need to create the custom code in steps 3 and 5 (in gray in the previous diagram) and find how to get them invoked within the CMS.
The previous explanation comes with a catch: you need to run custom code for every page view on your servers. This is fine if you have a small website like this blog, but if you have millions of page views per day, you will need a lot of processing power. This is the price to pay for a pure server-side implementation.
In the case of Adobe Experience Manager (AEM), the custom code will run in all publish instances. You have to configure the dispatcher not to cache HTML pages and always get them from the publisher. I am not an AEM expert, so I cannot give you any more advice. I believe you can optimize this setup to only call the publisher for fragments of the HTML instead of the full page, caching everything else, or only call the publisher for some HTML pages, caching the rest. If you are an AEM developer or architect, you are probably cringing by now. I know, I am very well aware that this proposal is totally against AEM’s best practices. However, server-side implementations require this drastic approach.
Content Delivery Network
There is still another catch. Most modern websites are “hidden” behind a Content Delivery Network (CDN). Even this blog uses one. This means that you will need to configure the CDN so that it does not cache HTML pages and, therefore, all requests to HTML pages are always served by the CMS. You can probably cache everything else (CSS, JS, assets…), reducing the load of your CMS. This is an improvement over the case without CDN. However, this configuration is still not optimal and many CDN & CMS experts will not easily accept it. As I said before, this is the price to pay if you do not want a client-side implementation.
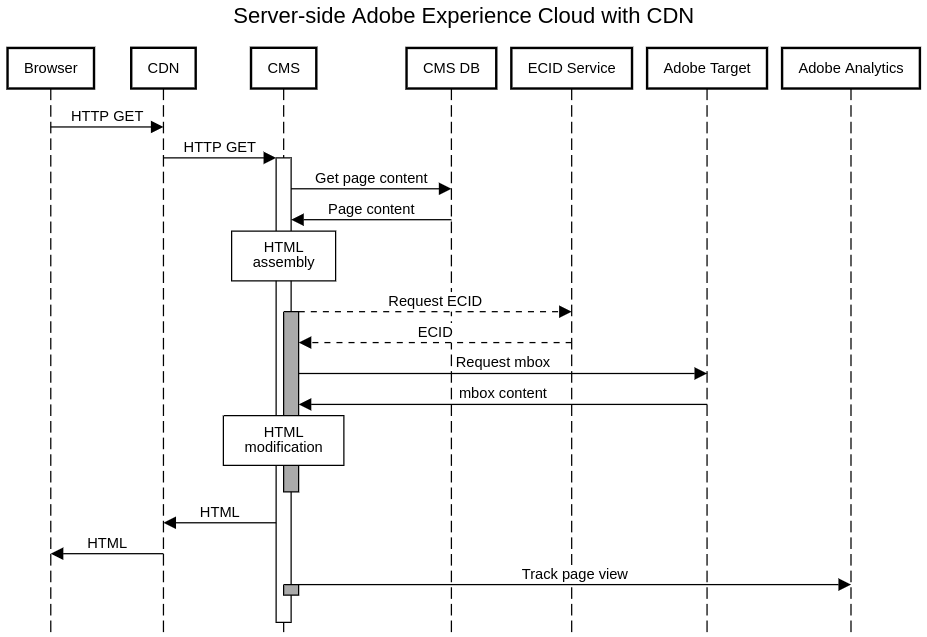
That being said, there may be a better solution. I have never tried it, though. It relies on a capability that some CDNs offer: edge workers. These are small pieces of code that run directly in the CDN infrastructure. My idea would be as follows:
- The browser requests a URL, which is routed to the closest CDN edge network.
- If the request is not for an HTML page, the CDN behaves as usual and returns the requested content.
- If the request is for an HTML page, an edge worker captures it and runs this process:
- Get the cached content for the page. If the cache is empty or stale, request the HTML from the origin.
- If there is no ECID in the request (AMCV cookie), request the ECID.
- Make a call to the Adobe Target delivery API.
- Process the response; if this response contains alternative content, modify the HTML page from step 3.a.
- Return the modified HTML.
- Make a call to the Adobe Analytics collection servers with the tracking beacon.
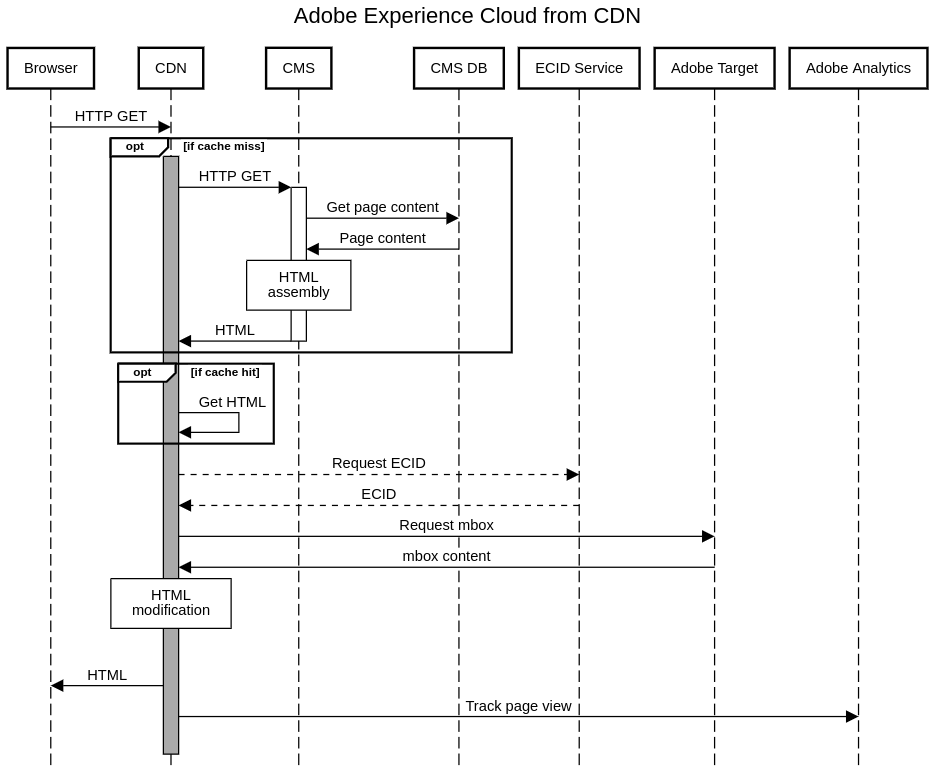
I would name this type of implementation “edge-side”. Let me know in the comments if you have managed to get something like this to work.
Offers and mboxes
I have skipped so far a crucial part of this whole process: how to set up the content in Adobe Target. In a typical client-side implementation, we use the Visual Experience Composer (VEC). This has two advantages:
- The VEC is a visual interface to apply modifications to a web page. There is no need to know CSS, JavaScript or HTML to use it.
- The output of the VEC is a set of instructions that both WebSDK and
at.jsunderstand.
In a pure server-side implementation, the VEC cannot be used, as there will be no WebSDK or at.js present. You will need to come up with your own standards and protocols for your server-side Adobe Target implementation. In particular, you will need to define the following:
-
Locations or mboxes. A server-side implementation requires the usage of local mboxes. The developer and the marketer will need to go through all templates and select which sections of a web page (i.e. which
<div>s) can be personalized or optimized. These<div>s will need to be marked somehow. In the Adobe Target world, these sections are called mboxes. -
Offer content types. Offers are snippets of content that can be used to replace default mbox contents. Adobe Target supports HTML, XML and JSON offers. If you are only going to support the replacement of content, that is, replacing the default HTML within the
<div>with a different HTML provided by Adobe Target, you can use HTML offers. For more advanced use cases, XML or JSON offers will probably be better suited, as you will need to provide both instructions and content. -
Rendering. I have been very vague in the previous sections about this point. Let me be a bit more explicit now. You will need to create some server-side code that takes a fully-built HTML, the default content from the CMS database, and modifies it according to the instructions provided in the offer. This is no easy task, as servers are not designed to do that. This code is going to be CPU intensive. You will probably need a library that:
- Parses the HTML.
- Generates a Document Object Model (DOM), as browsers do.
- Allows you to manipulate the DOM.
- Generates a new HTML based on the new DOM.
Final considerations
While I understand the appeal to move some Adobe client-side code to the server, as it will improve the page speed, other factors must also be considered:
- A server-side ECID service will not be able to set 3rd party cookies. As a consequence, there will be no ID syncs and using Adobe Audience Manager (AAM) will be severely limited.
- An Adobe Target server-side implementation is not marketer-friendly. It will require continuous support from IT for every activity. I would even argue that the benefits of a faster website are lost with the increased effort needed to launch new marketing campaigns.
- Removing code from the client means that more code must be executed on the server.
In a future post, I will explain a hybrid solution between server-side and client-side, specifically designed for Adobe Target.